Application from Sandbox to Production
This section explains how to promote code from Sandbox to Production.
If you create and test an application in a sandbox environment, you must move it to the production environment before deploying it. You must have the Cloud Hub Admin role to move applications between environments. Avoid name conflicts, rename the application before you deploy it to another environment. Runtime Manager prevents you from duplicating applications in a single environment, so you cannot move an application into the environment it’s already in. If you want to duplicate an application in a single environment, rename the filename of one application before you deploy it.
To move an application from sandbox to production:
- Sign into Any point Platform.
- Select Runtime Manager and switch to your production environment.
- In the Applications page, click Deploy application.
You see the Deploy Application page:
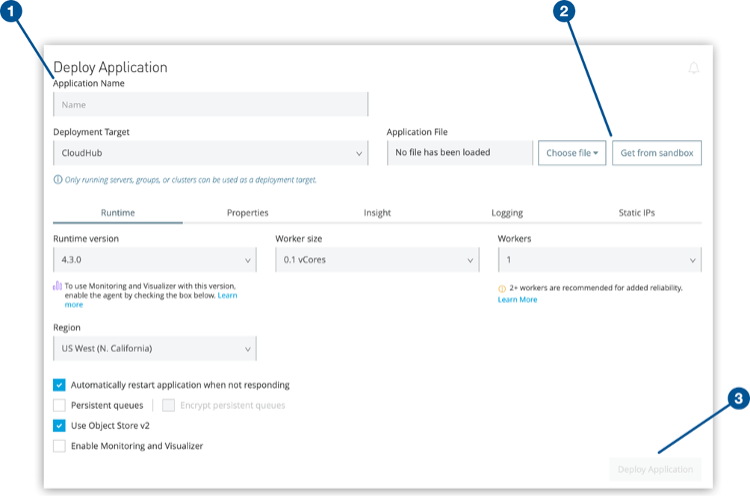
Figure 7
Above figure shows:
(1) Application Name field
(2) Get from sandbox button and
(3) Deploy Application button on the Deploy Application page.
- Provide a unique name for your application in production and click Get from sandbox. This button is unavailable if no nonproduction environment exists.
- Select your sandbox environment and then the application that you want to move to production.
Only applications that are deployed to Cloud Hub appear in the list because you can move only apps that are currently deployed to Cloud Hub to other Cloud Hub workers. For example, you cannot move an app that is currently deployed on a local server to Cloud Hub.
- If you want to copy the environment variables and Mule version from the source application, select Merge environment variables and mule version.
If your source application contains safely hidden application properties, you must redefine them in the Properties tab.
- Click Apply.
- Click tabs to configure application option.
- Click Deploy Application.
System Health Check:
After a successful deployment we can check the System Status by hitting the following endpoint.
Method: GET
Endpoint: http://productionurl/api/healthCheck
In the above endpoint, "productionurl" is the URL we need to point to our Production environment.
When a user hits the above URL, if the system is up and running, then response will be
{
“status”: “up”
}
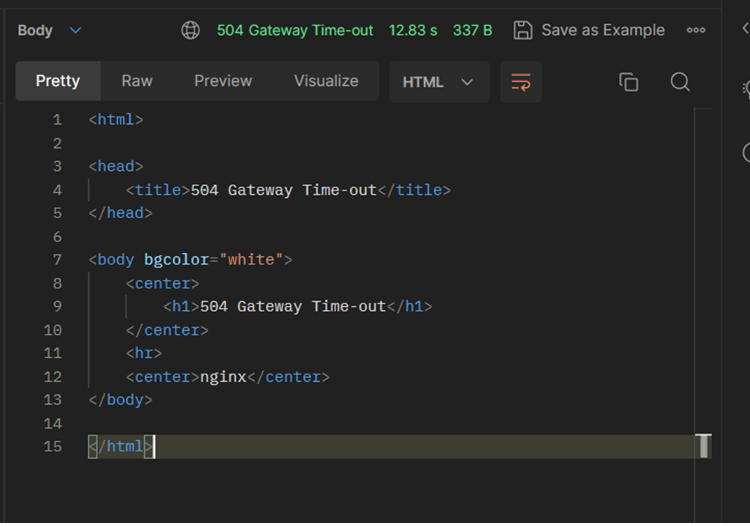
If the system is down and not running it will show the following error.
High Availability and Disaster recovery:
Cloud-Hub provides high availability (HA) and disaster recovery for application and hardware failures. Cloud Hub uses Amazon AWS for its cloud infrastructure, so availability is dependent on Amazon. The availability and deployments in Cloud Hub are separated into different regions, which in turn point to the corresponding Amazon regions. If an Amazon region goes down, the applications within the region are unavailable and not automatically replicated in other regions.
For example, if the US East region is unavailable, the CloudHub management UI, as well as the various REST services that enable deployments, are unavailable until the region’s availability is restored. New applications can’t be deployed while US East is down.
While the control plane is unavailable, the runtime plane continues to send log data and other telemetry data, which the worker buffers (up to 1 GB) until availability is restored.
CloudHub provides an internal messaging mechanism, in the form of persistent queues, that is used for message reliability. While persistent queues are highly available within a region, they might not be accessible if the region or part of the region is unavailable (usually a few seconds or minutes), which could result in some data loss. After the region is available again, CloudHub resumes communication with the queues.
Some CloudHub modules, such as Anypoint Object Store v1, application settings, and Insight-related information, are maintained in the US East region for all applications regardless of the region where they are deployed. Anypoint Object Store v2 is maintained in the same region as the deployed CloudHub application. For both Anypoint Object Store v1 and v2, if a region is unavailable, the data persists and becomes available again after the region returns to service.
Anypoint Virtual Private Cloud (Anypoint VPC) is set up at the region level. If a region is unavailable, Anypoint VPC is unavailable unless a previous Anypoint VPC instance is set up for the other region.
Anypoint CloudHub Default Deployment Model:
If the application uses multiple workers, CloudHub deploys the workers in separate availability zones by default, providing HA across availability zones. The distance between the availability zones is variable and generally doesn’t exceed 350 miles.
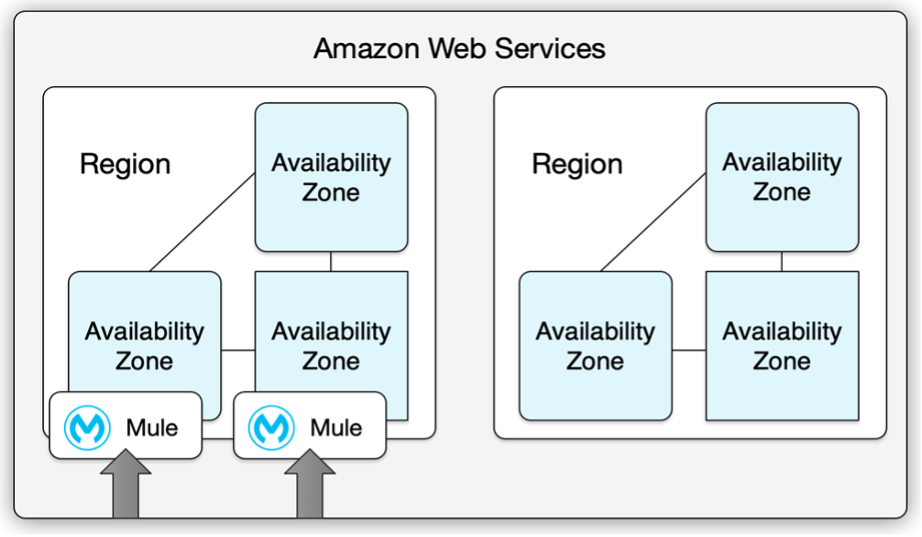
If an application uses a single worker, when the availability zone is unavailable, CloudHub automatically restarts the application in a different availability zone. In this case, the application might experience downtime.
You can set up status.mulesoft.com to receive alerts when a failure occurs in an availability zone or region.
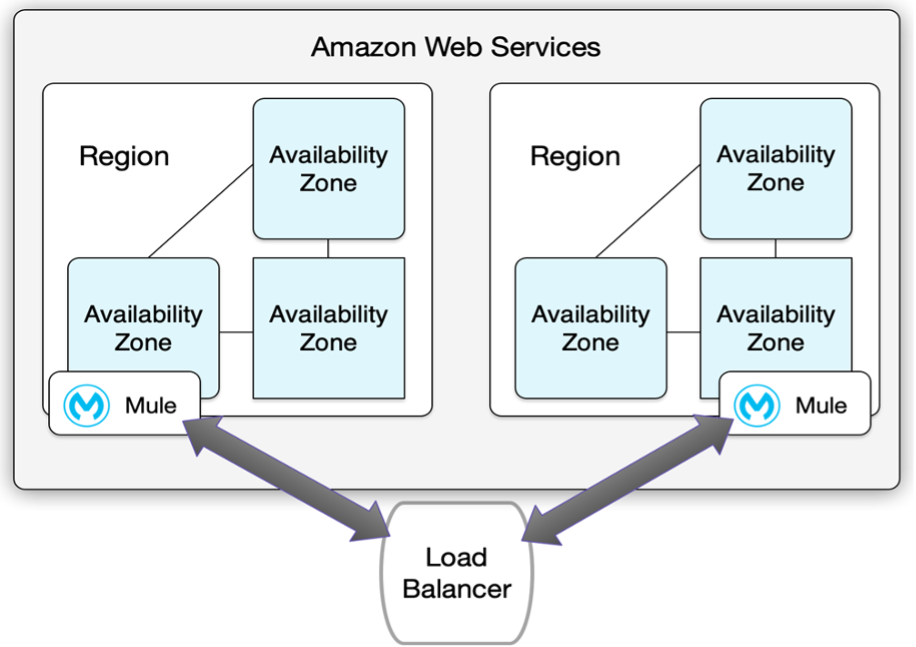
Suggested Alternative Deployment Model:
You can use a load balancer (cloud or on-premises) for applications deployed to different regions to provide a better disaster recovery strategy.
Deploying Mule for HA:
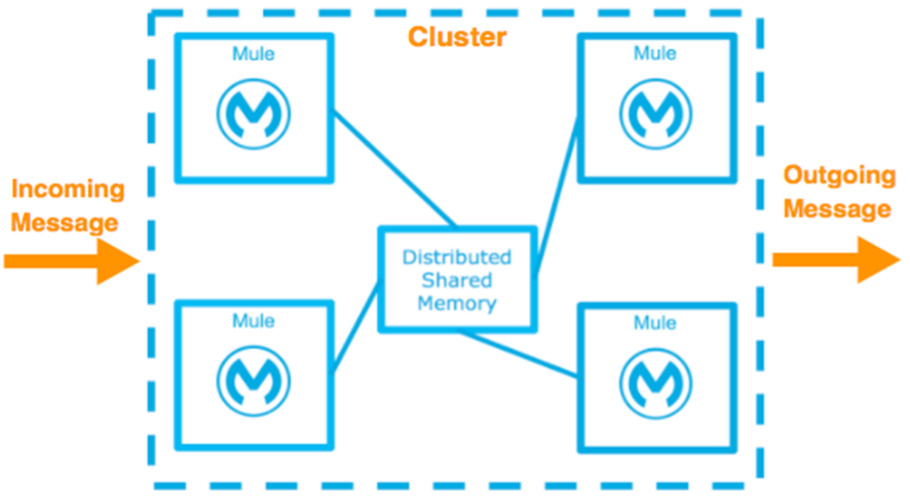
You can deploy the Mule Runtime in many different topologies to address your HA and DR strategies. One method is through the use of clustering, which is described later in this document. Mule High Availability Clustering provides basic failover capability for Mule.
When the primary Mule Runtime becomes unavailable, for example, because of a fatal JVM or hardware failure or it’s taken offline for maintenance, a backup Mule Runtime immediately becomes the primary node and resumes processing where the failed instance left off.After a system administrator recovers a failed Mule Runtime server and puts it back online, that server automatically becomes the backup node.
High Availability Options:
You can achieve high availability through the use of clustering and/or load balancing of the nodes. Depending on the defined SLA, four HA options are possible with Mule:
- Cold Standby
- Warm Standby
- Hot Standby-Active -Passive
- Active-Active
Cold Standby:
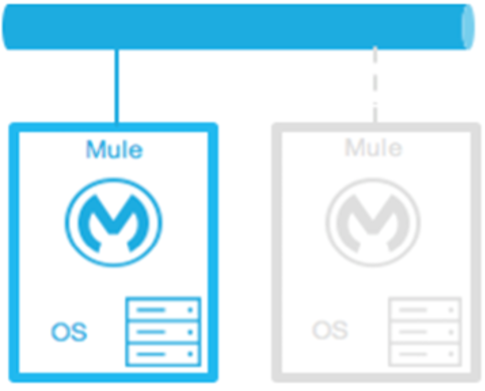
The Mule environment is installed and configured; however, one or more operating systems are not running. This can be a backup of a production system/virtual machine. The environment of the operating system plus the Mule Runtime has been started after an outage is detected.
Downtime: Some - The time it takes to start the environment and direct traffic
Warm Standby:
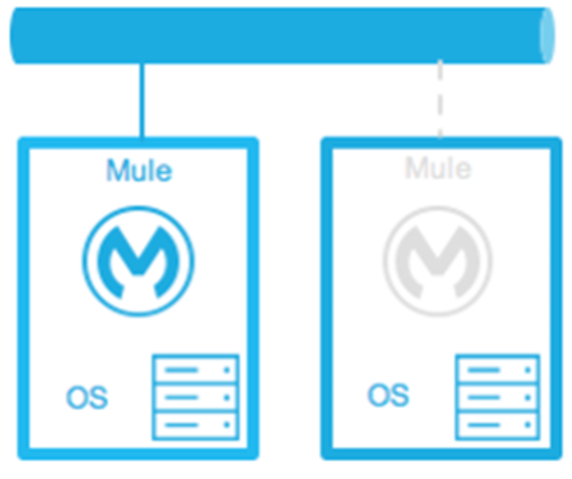
The Mule environment is installed and configured. However, the Mule Runtimes are not running, only the operating systems. The Mule Runtime is started after an outage is detected.
Down Time: Little—The time it takes for the Mule Runtimes to start and to route traffic to the environment.
Hot Standby— Active-Passive:
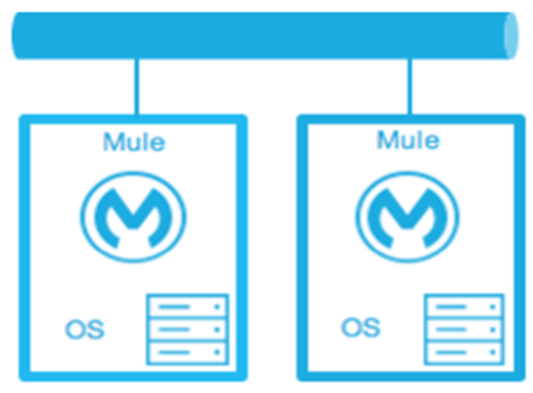
The Mule environment is installed, configured, and fully running. However, it is not processing requests until an outage is detected.
Down Time: Minimal to none - The time to route traffic to an environment.
Active-Active:
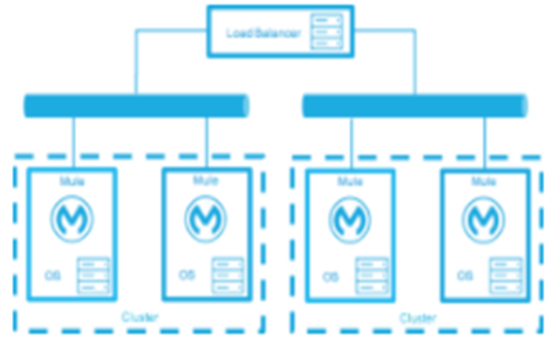
Load Balanced clustered environments there are two or more Mule environments (each environment has its own cluster) that are fully operational. The load balancer directs traffic to all environments.
Down Time: None - There is no service downtime
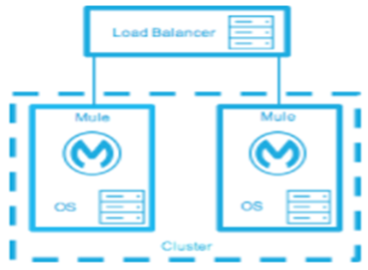
Load Balanced single clustered environment there are two or more Mule environments; however, they are part of the same clustered environment. To achieve this scenario, the network latency between environments must be less than 10ms.
Down Time: None - There is no service downtime.
Mule runtime IP Address:
This section explains how to obtain IP addresses of mule runtimes.
- Sign into Any point Platform.
- Select Runtime Manager

- Choose the Environment for which you need to obtain IP Address.
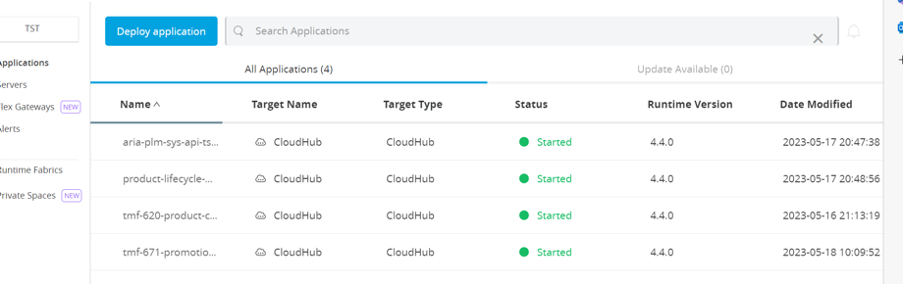
- Select application to see the IP Address respective worker